How to optimize Elasticsearch for search speed without breaking the bank
Jan 04 2022|Written by Slimane Akalië|programming
I. Wait a minute, what is Elasticsearch?
Elasticsearch is a search engine that is built on top of the Apache Lucene library, it can be used for multiple purposes: full-text search, data analytics, machine learning, auto-complete, spell checking, alerting, general-purpose document store and so much more.
If you are not familiar with Elasticsearch, I encourage you to check this video and prototype something using your laptop to get a clear idea. In this article, I assume you know how to interact with Elasticsearch.
For this article, we are taking the example of product search in an eCommerce website, but other use cases can also benefit from the recommendations.
II. Why search speed matters
In Simon Sinek fashion, let’s start with WHY? why we should minimize search response time on our eCommerce website?
The answer to this question can be found in Steve Jobs’ Stanford commencement address when he said
“Your time is limited, so don’t waste it living someone else’s life”.
All of our website users are thinking of something similar (at least subconsciously):
“My time is limited, so I shouldn’t waste it waiting for a response from Elasticsearch”
Once users’ time is wasted they become angry, and once they become angry they stop buying from your eCommerce store, and they tell their friends how terrible your product is, and those friends start telling their friends or share it on Twitter and so on, next thing you know you’re out of business. And that’s why you should optimize Elasticsearch for search speed.
Now the question becomes how to do it? the easy answer would be: add more nodes and pay for faster CPUs, but this solution can become too expensive and you can hit financial or physical limits on large amounts of data or high traffic, so your goal should be always getting results at the lowest cost possible (that’s why n is always better than n.log(n)).
That being said, doing some hardware improvements can help search speed like increasing RAM size, using faster disks (e.g: SSD drives instead of spinning disks), using faster CPUs, adding more nodes. However, changes like this should be taken after implementing software improvements without seeing any result and based on real data (increasing RAM when your CPU is at 100% won’t help you that much).
III. How to speed up searches (without any hardware upgrade)
Avoid joins and parent-child relationships
Let’s start with the famous mistake that most of us do when we move from a relational database to a document base database: making joins.
In Elasticsearch, joins hurt search performance and as it stated in the official doc:
In Elasticsearch the key to good performance is to de-normalize your data into documents.
So forget about the normal forms you studied in college and start treating Elasticsearch like a search engine, not a relational database.
Remove nested queries using de-normalization
Sometimes, you have some field in your documents that contains (or could contain) a nested object or an array of objects like this:
{
"group": "fans",
"user": [
{
"first": "John",
"last": "Smith"
},
{
"first": "Alice",
"last": "White"
}
]
}
If you stored this document directly without specifying the mapping of the field user beforehand, the field will be of type object and when you search for documents using a query like the following:
{
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" } },
{ "match": { "user.last": "Smith" } }
]
}
}
}
You will get the previous document as a match even though it doesn’t have a user called Alice Smith, it’s either John Smith or Alice White. This is happening because user.first and user.last are not associated anymore after storage because the type of field user is object to fix this you would have to use a nested type instead of object by specifying it on the index mapping when creating the index:
{
"mappings": {
"properties": {
"user": {
"type": "nested"
}
}
}
}
And to filter on the user field you use a nested query:
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" } },
{ "match": { "user.last": "Smith" } }
]
}
}
}
}
}
Nested fields are beneficial for arrays but nested queries are expensive, so you have to do two things:
First, NEVER use a nested field for a nested object, I know it looks nice to have a nested object but we’re not optimizing for good-looking data structures, we’re optimizing for search speed.
Second, always think about answering the same questions using de-normalization. One time, I remember we had a document that contained a field called
sponsoringwhich represents the history of sponsoring time intervals for a product with a start date and end date, and we needed to fetch sponsored products.Instead of storing an array of all the start and end dates, we could answer the query just by storing two fields: the minimum start date and maximum end date from all the sponsoring history.
{
"label": "Kindle paperwhite",
"description": "Preowned but still working fine.",
"min_sponsoring_start_timestamp": 151382906331,
"max_sponsoring_end_timestamp": 1741382906331
}
This small change helped us handle an additional large amount of requests without any hardware change.
Search using rounded dates
Following the previous example of sponsoring, to get the current products that are sponsored we had to use the now operator, so the query was something similar to the following:
{
"query": {
"bool": {
"must": [
{
"range": {
"min_sponsoring_start_timestamp": {
"lte": "now"
}
}
},
{
"range": {
"max_sponsoring_end_timestamp": {
"gte": "now"
}
}
}
]
}
}
}
This query by nature is not cacheable because the range that is being matched changes all the time (the “now” value changes). A small tweaking that we can do to take advantage of the query cache is to use a rounded date.
For example, we can round the above query by minute using now/m (if user experience permits this change) like this:
{
"query": {
"bool": {
"must": [
{
"range": {
"min_sponsoring_start_timestamp": {
"lte": "now/m"
}
}
},
{
"range": {
"max_sponsoring_end_timestamp": {
"gte": "now/m"
}
}
}
]
}
}
}
Now, if several users run the query in the same minute, the results will be served from the Elasticsearch query cache.
Use wildcard type when it’s appropriate
When you have a field that you anticipate to search using one or more of these types of queries:
- Wildcard queries
- Regexp queries
- Prefix queries
- Fuzzy queries
ALWAYS use a wildcard field type instead of keyword or text.
The queries mentioned above are expensive (time and resources) but using a dedicated field can help minimize this expense. Just keep in mind that search speeds for exact matches on full terms are slower than keyword.
You can create a wildcard field simply by adding it to the index mappings:
{
"mappings": {
"properties": {
"my_nice_wildcard": {
"type": "wildcard"
}
}
}
}
Add a document that contains this field:
{
"my_nice_wildcard": "This string can be quite lengthy"
}
And then search for it using a wildcard query for example:
{
"query": {
"wildcard": {
"my_nice_wildcard": {
"value": "*quite*lengthy"
}
}
}
}
Search as few fields as possible
In our imaginary eCommerce store, we need to give users the ability to search a product using a text input similar to what you see on Amazon and eBay:

And we know that every product has a label (iPhone X, Ferrari, Glasses) and a detailed description of the product with its characteristics, and these two fields are indexed into our Elasticsearch index respectively under the names label and description.
To get appropriate responses to the user query, we would need to take into consideration as many fields as we can, currently, we only have two.
It might seem fine to search these two fields using a terms query or a match-all query, and this would work but it won’t scale. When you search n fields you double the work (n-1) times, while this might be fine when you’re the only one doing product searches, it will be problematic when you have a large amount of traffic.
So we need to search as few fields as possible, in our case and a lot of similar cases, we can achieve this by copying the values of all the fields we want to search into one single field.
Instead of having something like this:
{
"label": "iPhone X",
"description": "An expensive phone without accessories. Thanks"
}
We can add a new field label_description and use it to full-text search:
{
"label": "iPhone X",
"description": "An expensive phone without accessories. Thanks",
"label_description": "iPhone X An expensive phone without accessories. Thanks"
}
We can either add this field on indexing or automate it using the copy_to directive.
Pre-index data
Now the full-text search is working on our store but a product manager suggests adding a price range filter on products to help users get products that they can afford, something similar to what eBay does.
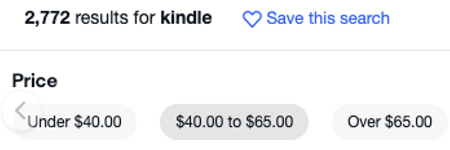
Because you know there is a price field on our product documents, you thought of using a range query. And you’re right, we can fulfill this requirement using a range query, however, range queries can be expensive and you can avoid using them by pre-indexing.
When indexing a product, we can simply define its range based on its price, so we would have something similar to this on our index:
{
"label": "Kindle paperwhite",
"description": "Preowned but still working fine.",
"label_description": "Kindle paperwhite Preowned but still working fine.",
"price_usd": 55,
"price_range": "40-65"
}
Now when the user wants to see products that are in the price range of 40 USD to 65 USD, you can simply search using a term query:
{
"query": {
"term": {
"price_range": "40-65"
}
}
}
Use keyword field type whenever you can
Just because the value of a field is numeric doesn’t mean the field should be indexed as a numeric field. The numeric fields are optimized for range queries. keyword fields are better for term and other term-level queries.
Product ID for example would rarely be used in a range query but it will potentially receive a lot of term-level queries.
If you’re unsure which type to use, you can use a multi-field to map the data as both a keyword and a numeric data type (just pay attention to the storage cost).
Avoid using terms query
In our eCommerce store, we want to give users the ability to search in categories (Phones, Laptops, Homes ... etc) and also search in verticals (Electronics, Real estate, Decoration ..etc). We know the category of each product because each document on our Elasticsearch index has a category_id field:
{
"label": "Kindle paperwhite",
"description": "Preowned but still working fine.",
"label_description": "Kindle paperwhite Preowned but still working fine.",
"price_usd": 55,
"price_range": "40-65",
"category_id": "3"
}
We also have a simple JSON config file that contains which vertical a category belongs to:
{
"1": {
"category_id": "1",
"category_name": "Homes",
"vertical_id": "200"
},
"2": {
"category_id": "2",
"category_name": "Cars",
"vertical_id": "300"
},
"3": {
"category_id": "3",
"category_name": "Phones",
"vertical_id": "100"
},
"4": {
"category_id": "4",
"category_name": "Computers",
"vertical_id": "100"
},
"5": {
"category_id": "5",
"category_name": "Motocycles",
"vertical_id": "300"
}
}
And another config file that contains the subcategories of each vertical:
{
"100": {
"vertical_id": "100",
"vertical_name": "Electronics",
"subcategories_ids": ["3", "4"]
},
"200": {
"vertical_id": "200",
"vertical_name": "Real estate",
"subcategories_ids": ["1"]
},
"300": {
"vertical_id": "300",
"vertical_name": "Vehicles",
"subcategories_ids": ["2", "5"]
}
}
Search by product category can simply be answered using a term query:
{
"query": {
"term": {
"category_id": "3"
}
}
}
But how can we search for products by vertical?
One solution would be using a terms query because we have the verticals config. So, to search for all the products in the Electronics vertical for example we could use this terms query:
{
"query": {
"terms": {
"category_id": ["3", "4"]
}
}
}
This might be fine with two categories, but with more categories per vertical, it gets slower the more terms we add. To solve this issue, on indexation we will add a new keyword field to our product called vertical_id based on the config we have, so the previous Kindle document would now look something like this:
{
"label": "Kindle paperwhite",
"description": "Preowned but still working fine.",
"label_description": "Kindle paperwhite Preowned but still working fine.",
"price_usd": 55,
"price_range": "40-65",
"category_id": "3",
"vertical_id": "100"
}
And the query to search for products in the Electronics vertical will become much simpler and faster:
{
"query": {
"term": {
"vertical_id": "100"
}
}
}
Use force-merge to your benefit
I remember one time we’ve had a high search latency on our Elasticsearch cluster without any unusual increase in traffic, the problem was visible on our normal peak hours but nothing was unusual. When we dug deeper into the metrics, we found that Elasticsearch started the process of automatic merging of segments which is resource consuming (especially with us using the default config for segments).
To fix the issue, I had to make sure our segments are merged outside of peak hours.
To achieve this I took two steps:
Limit the probability of triggering automatic merging by updating merging policy settings on our index:
- Decrease index.merge.policy.segments_per_tier to a smaller number
- Decrease index.merge.policy.max_merge_at_once to a smaller number
- Decrease index.merge.policy.max_merge_at_once_explicit to a smaller number
- Increase index.merge.policy.deletes_pct_allowed to a bigger number
More on this config here.
Trigger manual merge outside peak hours using a cronjob, the cronjob does the following in order (order is very important):
- Stop temporarily the Elasticsearch indexer (a separate program that indexes data on Elasticsearch) → make sure you save the indexer state before stopping it
- Make the Elasticsearch index read-only
- Call the force merge API on the index
- Make the Elasticsearch index write eligible
- Start the Elasticsearch indexer
After implementing these changes, I saw a good improvement in response time and more predictable segment merges (outside peak hours of course).
Use index sorting
If by default we range results on our eCommerce store using a field, we can use that field also to specify how segments inside each shard are sorted, like this we can have faster access to recent products. This is called index sorting.
For example, if we always rank products on our store by price in ascending order we can sort the index according to the price field on creation.
{
"settings": {
"index": {
"sort.field": "price_usd",
"sort.order": "asc"
}
}
}
Index sorting setting can’t be updated after index creation but you can use reindex API to create a new separate index.
Use a preference to benefit from caching
Imagine we have 4 Elasticsearch nodes on our cluster and an index with 1 primary shard and 3 replicas.
If we receive the same query 4 times, the expected behavior would be something similar to this:
- Node 1 receives the query Q and performs the search (nothing on the different caches), returns the response, and stores the result in a cache (filesystem, request, or query cache).
- Next, node 2 receives the query Q and performs the search (nothing on the different caches), returns the response, and stores the result in a cache.
- Next, node 3 receives the query Q and performs the search (nothing on the different caches), returns the response, and stores the result in a cache.
- Next, node 4 receives the query Q and performs the search (nothing on the different caches), returns the response, and stores the result in a cache.
There is something problematic here. If we could route the query Q to node 1 always we would be using caches and get faster responses, but how do we do this when the default routing algorithm is round-robin? enters preference.
You can use preference directive to help decide which node handles your query, in our case, we can use a session id or something similar to route the query Q always to the same node x.
Choose the right number of shards
Elasticsearch documentation has a very informative article about this subject, but to keep it simple:
- More shards: faster indexing and slower search
- Fewer shards: faster search and slower indexing
You have to find the balance between both, a rule of thumb is to keep the shard size below 50 GB, so if your index size is less than 50 GB just use one shard.
Also, pay attention to unused nodes. If you have an index with 1 primary shard and 2 replicas on a 4 nodes cluster, then an Elasticsearch node is not used, remember to always have:
number of primary shards + (number_of_replicas * number of primary shards) ≥ number of nodes
Stop tracking number of hits
When you search for something on Google, you get the number off all the results (millions usually) but you have access to just a couple of results per page for a better user experience.

You can achieve something similar using from and size query params but Elasticsearch counts the matches in the field hits.total. Tracking the total number of results can be expensive because it can’t be computed accurately without visiting all matches, which is costly for queries that match lots of documents. That’s why Elasticsearch has a default limit of 10000 matches (which is still a lot).
What you can do to prevent this calculation is to set track_total_hits to false on your search query.
And to get all the result counts you can use a separate query (with the same filters) based on the Count API that is optimized to such operations.
Increase refresh interval
Making a document visible for search is an operation that is called a refresh.
This operation is costly, by default Elasticsearch periodically refreshes indices every second, but only on indices that have received one search request or more in the last 30 seconds.
The default config can be problematic if you have even moderate search traffic, and this can slow the searches. To mitigate this, you can increase the refresh interval to a longer period based on what is acceptable in your use case:
{
"index": {
"refresh_interval": "180s"
}
}
IV. Conclusion
In the end, your only source of truth is your Elasticsearch dashboard, and to get the search speed where you want it to be, your only guaranteed weapon is experimentation.
Define what matters for your use case, read about how Elasticsearch works under the hood, tune-up the software and measure the impact of every action you take (maybe rollback if necessary), and don’t assume things you didn’t find in the documentation of your Elasticsearch version (Elasticsearch 6.x is not Elasticsearch 7.x, and Open Search is not 100% identical to Elasticsearch).